The Garmin 645 Music watch is a running watch with 3.5 GB of on board media storage and Bluetooth capability. An impressive but limited set of apps is available to manage and play podcasts on the watch, most notably playrun.app. Unfortunately, there is no playback speed functionality built in to the watches audio player and it is really hard to go back to listening to podcasts at 1x speed. In this project we'll set up a podcast RSS mirror that sends out a sped-up version of all your favorite podcasts as they are released.
Note - the result here is meant for personal use. Altering the audio content and re-distributing may be infringement of copyright.
The results of this project can be found here.
Project
Here's the end goal we have in mind and the tools we can use to do all the heavy lifting:

Our Python script is pretty simple. We'll start off by pulling in some libraries that allow us to deal with the local filesystem and manipulate XML files:
import os
import xml.etree.ElementTree as ETThen we'll define what podcasts we want to mirror and the speedup factor we want to use for each. We need to locate the RSS feed for each podcast to know where to download from. The best way I found to locate the RSS feed is to look up the Podcast on PodBean, it shows the RSS feed just below the title:

We'll collect the podcast identifier, the show-specific speedup, and the rss feed into a list of tuples. I picked a few of the more prolific podcasts from among my favorites.
pods = [
("80k", "1.8", "https://feeds.feedburner.com/80000HoursPodcast"),
("ezra", "1.8", "https://feeds.simplecast.com/82FI35Px"),
("lex", "1.8", "https://lexfridman.com/feed/podcast/"),
("rspeak", "1.8", "https://rationallyspeakingpodcast.libsyn.com/rss"),
("tyler", "1.8", "https://cowenconvos.libsyn.com/rss"),
("econ", "1.8", "http://files.libertyfund.org/econtalk/EconTalk.xml"),
("mscape", "1.8", "https://rss.art19.com/sean-carrolls-mindscape"),
]And then for each podcast we start by pulling in its feed as a .xml file, parsing it, and finding the latest "item" entry which contains the latest episode:
os.system("wget " + pod[2] + " -O raw.xml")
tree = ET.parse("raw.xml")
root = tree.getroot()
ep = root.find('./channel/item')Then we can pull out some information about the episode:
ep_id = ep.find('guid').text
ep_title = ep.find('title').text
ep_audio = ep.find('enclosure').attrib['url']
ep_date = ep.find('pubDate').textWe'll make a name for the file out of the title (minus any funny characters) and specify its target directory as ./audio/podcastname/episodename.mp3:
file_name = "".join([c for c in ep_title if c.isalpha() or c.isdigit()]).rstrip() + ".mp3"
full_file = os.path.join("audio", pod[0], file_name)We can check if we already pulled this podcast by seeing if that file already exists. If not, let's download the audio and run it through ffmpeg to compress the tempo. I tried the different quality levels (detailed here) and couldn't tell the difference between 1-6. A trained ear may disagree. Git file limits are 100MB, so quality 6, at an average bitrate of 115 kbit/s, should net of sped up audio, or of original speed audio assuming 1.8x speed up. That should be sufficient compression to hold all but the longest episodes.
if not os.path.exists(full_file):
os.system("wget \"" + ep_audio + "\" -O raw.mp3")
os.system("ffmpeg -i raw.mp3 -filter:a \"atempo=" + pod[1] + "\" -q:a 6 " + full_file)Finally, we'll add the item to our existing feed.xml file. A minimal feed.xml looks like:
<rss version="2.0">
<channel>
<title>Jacob's 1.8</title>
<language>en-us</language>
<description>A few select podcasts preprocessed at 1.8x</description>
</channel>
</rss>To add the new item we'll make a new XML element and insert it. The episode URL will come from the Github raw content link for this directory.
#Make the new XML item element
new_item = ET.Element('item')
new_title = ET.Element('title')
new_title.text = pod[0] + " " + ep_title
new_enclosure = ET.Element('enclosure',
url="https://raw.githubusercontent.com/jacobwood27/032_fastaudiocasts/main/audio/" + pod[0] + "/" + file_name,
length=str(os.path.getsize(full_file)),
type="audio/mpeg")
new_guid = ET.Element("guid")
new_guid.text = ep_id + "_1.8x"
new_pubdate = ET.Element("pubDate")
new_pubdate.text = ep_date
new_item.append(new_title)
new_item.append(new_enclosure)
new_item.append(new_guid)
new_item.append(new_pubdate)
feed_chan.insert(3, new_item) #after title, language, and description
feed.write('feed.xml')Run the Python script once, commit it all to Github (or fork mine) and enable Github Pages for that directory and your RSS feed should be up and running! You can test it easily by opening the feed in VLC.
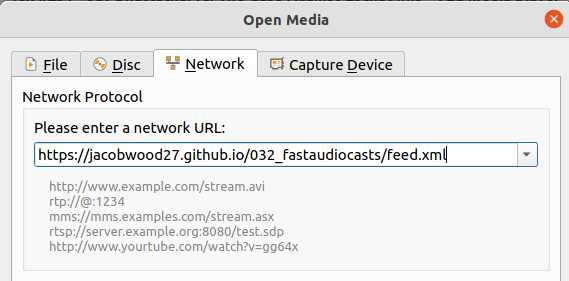
To keep the feed up to date we want to run that Python script about once a day. Github Actions is a convenient set-it-and-forget-it way to do this. We'll add a new action to the repository and tell it to run every day at some specific time.
name: Get New Podcasts
on:
schedule:
# * is a special character in YAML so you have to quote this string
- cron: '30 5 * * *'
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout latest
uses: actions/checkout@v2
- name: Set up Python 3.10
uses: actions/setup-python@v2
with:
python-version: "3.10"
- name: Set up ffmpeg
uses: FedericoCarboni/setup-ffmpeg@v1.1.0
- name: Run Script
run: |
python make_rss.py
- name: Commit and Push
run: |
git config --global user.name "github-actions[bot]"
git config --global user.email "41898282+github-actions[bot]@users.noreply.github.com"
git add -A
git commit --allow-empty -m "Update"
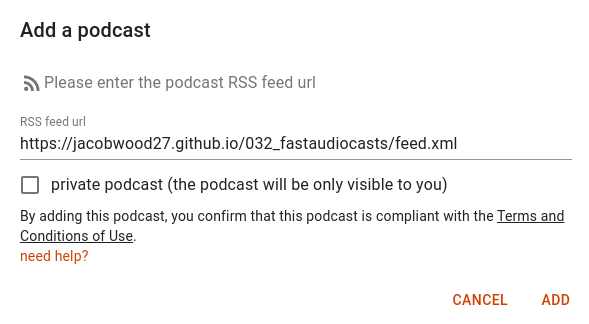
git pushThe last thing to do is add your new feed to the playrun.app (or your player of choice) interface and sync your watch.

Ingredients
playrun - Garmin App to sync and play podcast feeds
Github Actions - Github feature to automate a software workflow
Github Pages - Github feature to host a website from a repository
Python 3.9.7 - Scripting language
ffmpeg 4.4-6 - Media conversion tool that can do anything
ffmpeg Github Action - Github action to leverage ffmpeg in your workflow